Working with Files
QuickFlo provides a full set of file operations for reading, writing, downloading, and managing files in your workflows. Every file step supports both managed storage (zero-config, hosted by QuickFlo) and bring-your-own cloud storage providers.
Available File Steps
Section titled “Available File Steps”| Step | What it does |
|---|---|
| file.write | Write content to a file in cloud storage |
| file.read | Read a file’s content from cloud storage |
| file.download-from-url | Download a file from an HTTP(S) URL |
| file.delete | Delete a file from cloud storage |
| file.copy | Copy a file to a new path |
| file.move | Move a file to a new path |
| file.list | List files in a storage directory |
| file.exists | Check whether a file exists at a given path |
| file.get-signed-url | Generate a temporary signed URL for secure file access |
| file.generate-pdf | Render an HTML string into a PDF file written to cloud storage |
Storage Options
Section titled “Storage Options”Every file step that interacts with cloud storage includes a Storage section with four tabs:
Managed Storage
Section titled “Managed Storage”The default option. Files are stored in QuickFlo’s hosted storage, scoped to your organization. No configuration needed — just provide a file path and QuickFlo handles the rest.
Managed storage paths are relative to your organization’s namespace. For example, writing to reports/monthly.csv stores the file at an organization-scoped path that only your workflows can access.
Google Cloud Storage
Section titled “Google Cloud Storage”Connect your own GCS bucket. Provide a service account key and reference files using gs:// URLs (e.g., gs://my-bucket/data/file.csv).
Amazon S3
Section titled “Amazon S3”Connect any S3-compatible storage — AWS S3, Cloudflare R2, MinIO, and others. Provide an access key, secret key, region, and bucket. Reference files using s3:// URLs.
Connect to an SFTP server for file operations. Provide host, port, username, and authentication credentials. Reference files using sftp:// URLs.
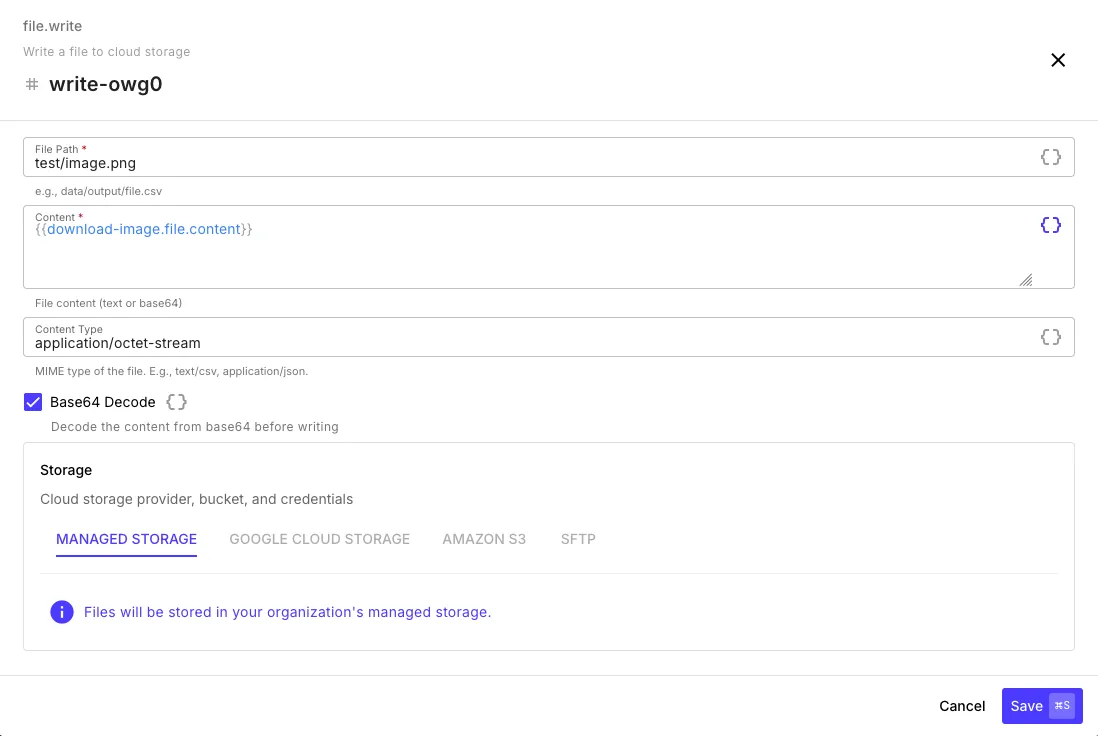
Writing Files
Section titled “Writing Files”The file.write step saves content to cloud storage.
| Field | Description |
|---|---|
| File Path | Where to store the file (e.g., data/output/report.csv) |
| Content | The file content — use templates to pass data from previous steps |
| Content Type | MIME type of the file (e.g., text/csv, application/json) |
| Base64 Decode | Enable when the content is base64-encoded (e.g., binary files from an API response) |
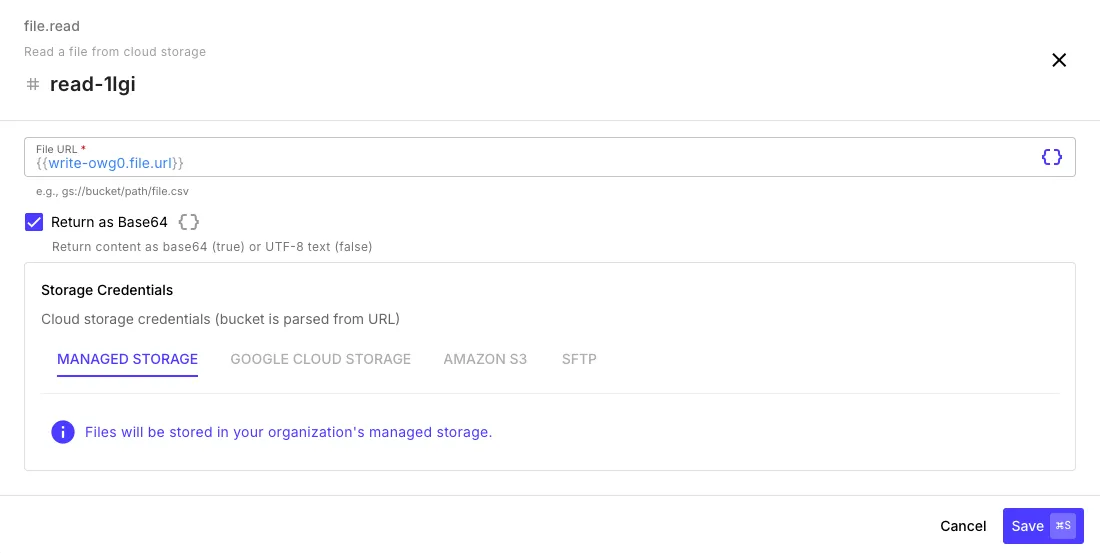
Reading Files
Section titled “Reading Files”The file.read step retrieves a file’s content from cloud storage.
| Field | Description |
|---|---|
| File URL | The storage URL of the file — use the url from a previous write step’s output (e.g., {{ write-step.file.url }}) |
| Return as Base64 | Return content as base64 instead of UTF-8 text — use this for binary files like images or PDFs |
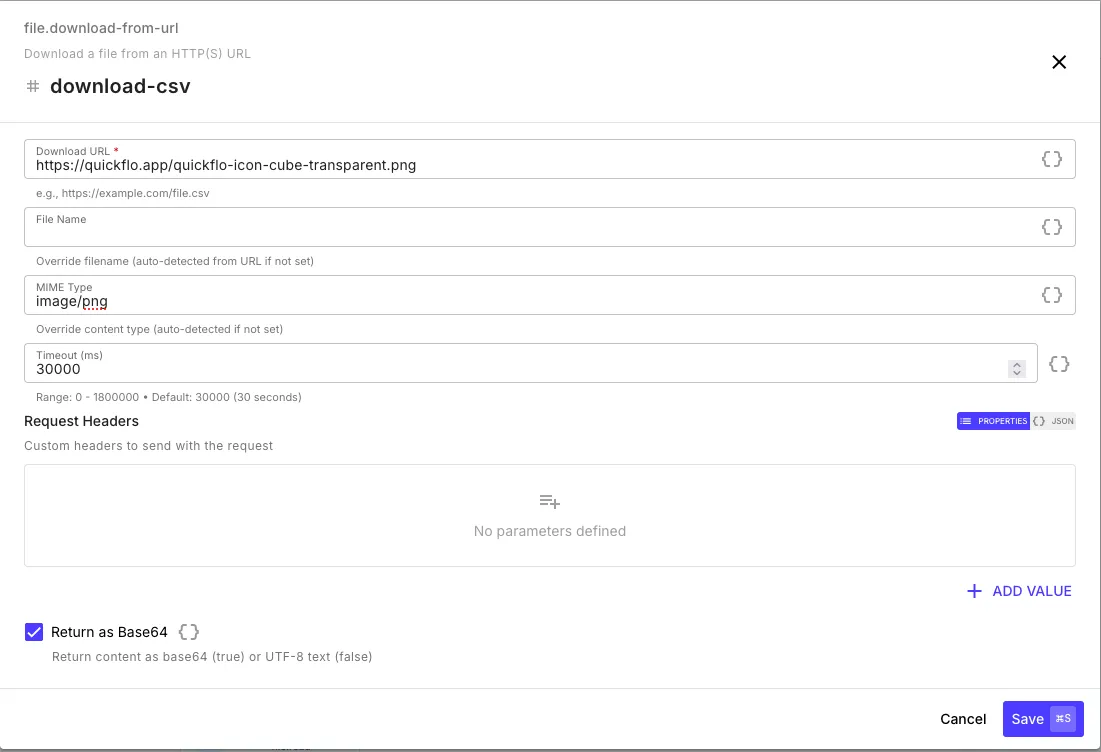
Downloading from a URL
Section titled “Downloading from a URL”The file.download-from-url step fetches a file from any public HTTP(S) URL and returns it as a file object you can pass to other steps.
| Field | Description |
|---|---|
| Download URL | The HTTP(S) URL to download from |
| File Name | Override the auto-detected filename |
| MIME Type | Override the auto-detected content type |
| Timeout | Max wait time in milliseconds (default: 30,000) |
| Request Headers | Custom headers to send with the download request (e.g., auth tokens) |
| Return as Base64 | Return the downloaded content as base64 |
Generating Signed URLs
Section titled “Generating Signed URLs”The file.get-signed-url step creates a temporary, pre-authenticated URL for accessing a file without exposing your storage credentials.
| Field | Description |
|---|---|
| File URL | The storage URL of the file |
| Expires In | How long the signed URL remains valid (in minutes, default: 60) |
Output:
{{ get-signed-url-step.signedUrl }} // Temporary public URL{{ get-signed-url-step.originalUrl }} // Original storage URL (gs://, s3://, etc.){{ get-signed-url-step.expiresAt }} // Expiration timestampGenerating PDFs
Section titled “Generating PDFs”The file.generate-pdf step renders HTML into a PDF and writes it to cloud storage. Useful for invoices, reports, exports, or any “give me back a PDF” workflow.
| Field | Description |
|---|---|
| Source | Where the HTML comes from — inline (paste HTML directly), stored-file (HTML file already in storage), or public-url (fetch HTML from a URL) |
| Filename | Name of the resulting PDF (default: document.pdf) |
| CSS | Optional custom CSS string applied on top of the document |
| Include Base Styles | If true (default), QuickFlo applies a baseline stylesheet so unstyled HTML still renders cleanly |
| Page Size | A4 (default), Letter, Legal, A3, A5, or Tabloid |
| Landscape | If true, render in landscape orientation (default false) |
| PDF Features | Optional add-ons: page numbers (with position and format), bookmarks (default on), a running header, and document info (title, author, subject) |
| Storage | Same provider tabs as the other file steps (managed, GCS, S3, SFTP) |
The output is a standard file object pointing at the generated PDF (URL only — the binary content isn’t returned in workflow context to avoid bloat) plus a pageCount field. Pipe the file into file.get-signed-url to return a download link from a webhook trigger, or attach it to an email.
File Object Output
Section titled “File Object Output”Steps that produce files (download-from-url, read, write, generate-pdf) return a file object on success or a fileError object on failure. You can branch on which one is present.
Success — file object
Section titled “Success — file object”{{ download-step.file.filename }} // e.g., "report.csv"{{ download-step.file.content }} // File content (text or base64){{ download-step.file.mimeType }} // e.g., "text/csv"{{ download-step.file.size }} // File size in bytes{{ download-step.file.url }} // Source URLFailure — fileError object
Section titled “Failure — fileError object”When a file operation fails (missing credentials, file not found, network failure, etc.) the step returns a fileError object instead of file. The step still completes successfully from the workflow’s perspective, so you can detect and handle the error inline:
{{ read-step.fileError.message }} // Human-readable error message{{ read-step.fileError.code }} // Taxonomy error code (see table below)File error codes
Section titled “File error codes”fileError.code is one of a stable set of QuickFlo taxonomy codes — extracted from whatever the underlying storage SDK threw and mapped to a vocabulary you can branch on:
| Code | Cause | Meaning |
|---|---|---|
FILE_NOT_FOUND | permanent | File or path does not exist |
FILE_ACCESS_DENIED | permanent | Storage backend rejected the operation (ACL / IAM) |
INVALID_CREDENTIALS | permanent | Storage credentials invalid, expired, or missing scopes |
BUCKET_NOT_FOUND | permanent | Target bucket / container does not exist |
QUOTA_EXCEEDED | permanent | Storage account quota or plan limit reached |
INVALID_PATH | permanent | Path is invalid for this backend (illegal chars, too long) |
STORAGE_TIMEOUT | transient | Timed out talking to the backend |
STORAGE_CONNECTION_FAILED | transient | Could not reach the backend (DNS / connection reset) |
STORAGE_RATE_LIMITED | transient | Backend throttled the request (S3 SlowDown, GCS 429) |
STORAGE_TEMPORARILY_UNAVAILABLE | transient | Backend returned a 5xx |
STORAGE_UNKNOWN_ERROR | unknown | Unclassified — retried by default |
The same codes drive the engine’s retry decisions — see Error Handling → Which step types have taxonomies.
Branch on which one is present:
{% if read-step.fileError %} Skipping — {{ read-step.fileError.message }}{% else %} Got file: {{ read-step.file.filename }}{% endif %}Common Patterns
Section titled “Common Patterns”Download and store a file
Section titled “Download and store a file”Download a file from an external API, then write it to managed storage:
Step 1 (file.download-from-url): Download from https://api.example.com/export.csvStep 2 (file.write): Path = exports/{{ initial.date }}.csv Content = {{ download-step.file.content }}Generate a download link
Section titled “Generate a download link”Write a file to storage, then create a signed URL to return to the caller:
Step 1 (file.write): Path = reports/{{ initial.reportId }}.pdfStep 2 (file.get-signed-url): File URL = {{ write-step.file.url }}Step 3 (return): Body = { "downloadUrl": "{{ get-signed-url-step.signedUrl }}" }Read, transform, and re-write
Section titled “Read, transform, and re-write”Read a file, process its content with a data step, then write the result back:
Step 1 (file.read): File URL = gs://my-bucket/raw/data.jsonStep 2 (data.map): Transform the parsed contentStep 3 (file.write): Path = processed/data.json, Content = {{ map-step.output }}